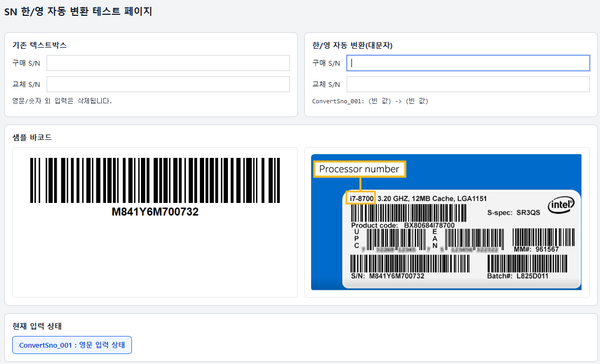
한글 입력 상태에서도 S/N이 깨지지 않게 만든 바코드 입력 보정 스크립트

제품 S/N을 바코드 리더기로 스캔할 때 은근히 자주 발생하는 문제가 있다.
입력창에 커서를 두고 바코드를 스캔했는데, Windows 입력 상태가 한글이면 영문 S/N이 정상적으로 들어가지 않는다.
예를 들어 원래 입력되어야 하는 값이 아래와 같다면,
ACE123
한글 입력 상태에서는 이런 식으로 들어갈 수 있다.
ㅁㅊㄷ123
또는 브라우저, 전산 페이지, IME 상태에 따라 입력이 비정상적으로 처리되는 경우도 있다.
이럴 때마다 해야 하는 작업은 거의 비슷하다.
1. 잘못 입력된 값을 지운다.
2. 한/영 키를 눌러 영문 입력으로 바꾼다.
3. 다시 바코드를 스캔한다.
한두 번이면 괜찮다.
하지만 제품 S/N을 계속 입력해야 하는 업무에서는 이 과정이 꽤 번거롭다.
그래서 한글 입력 상태에서도 S/N을 영문 대문자로 자동 정리해주는 입력 보정 스크립트를 만들었다.
프로젝트 이름은 ko-sn-ime-auto-convert다.
GitHub 저장소: HoMongYi/ko-sn-ime-auto-convert
왜 만들었나
문제의 원인은 바코드 리더기가 특별한 방식으로 값을 넣는 것이 아니라, 대부분 키보드 입력처럼 문자열을 빠르게 입력한다는 점에 있다.
즉, 사용자가 직접 키보드로 ACE123을 입력하는 것과 비슷하게 동작한다.
그런데 Windows 입력 상태가 한글이면 물리적으로는 A, C, E 위치의 키가 들어와도, 입력 결과는 한글 자모로 조합될 수 있다.
그래서 ACE123이 아니라 ㅁㅊㄷ123처럼 입력되는 것이다.
이 문제는 사용자 교육만으로 해결하기 어렵다.
스캔하기 전에 항상 한/영 상태를 확인하세요.
말은 쉽지만, 실제 업무에서는 반복 작업 중에 놓치기 쉽다.
입력 실수는 결국 다시 지우고 다시 스캔하는 시간 낭비로 이어진다.
그래서 사용자가 입력 상태를 신경 쓰지 않아도 되도록, 입력창 쪽에서 값을 자동으로 보정하는 방식으로 접근했다.
해결 방식
방식은 단순하다.
S/N 입력창에 들어온 값을 감지한 뒤, 아래 순서로 값을 정리한다.
1. 한글 IME 상태로 들어온 두벌식 한글을 QWERTY 영문 키 입력으로 되돌린다.
2. 영문과 숫자만 남긴다.
3. 최종 값을 대문자로 정리한다.
4. 화면에 보이는 값뿐 아니라 실제 input.value도 정리된 값으로 바꾼다.
예를 들면 이런 식이다.
ㅁㅊㄷ123 → ACE123
asdf123 → ASDF123
A-C E 123 → ACE123
이렇게 하면 바코드 스캔, 직접 입력, 복사/붙여넣기 모두 같은 기준으로 정리할 수 있다.
프로젝트 구성
저장소 구성은 단순하다.
ko-sn-ime-auto-convert/
├─ sn-ime-auto-convert.js # 운영 페이지에 적용할 핵심 스크립트
├─ demo.html # 기존 입력 방식과 자동 변환 입력을 비교하는 데모 페이지
├─ sample-sn-barcode.png # 스캔 테스트용 샘플 S/N 바코드 이미지
└─ sample-sn-label.png # S/N 라벨 예시 이미지
핵심은 sn-ime-auto-convert.js 파일 하나다.
운영 페이지에서는 이 파일을 불러온 뒤, S/N 입력창 selector를 지정해서 적용하면 된다.
<script src="./sn-ime-auto-convert.js"></script>
<script>
document.addEventListener('DOMContentLoaded', function () {
applySnImeAutoConvert('#Sno_001, #SnoChange_001');
});
</script>
여러 개의 S/N 입력창에 한 번에 적용해야 한다면 id prefix selector를 사용할 수도 있다.
<script src="./sn-ime-auto-convert.js"></script>
<script>
document.addEventListener('DOMContentLoaded', function () {
applySnImeAutoConvert('input[id^="Sno_"], input[id^="SnoChange_"]');
});
</script>
동적으로 입력창이 추가되는 구조라면, 입력창을 만든 뒤 applySnImeAutoConvert()를 다시 호출하면 된다.
이미 적용된 입력창에는 이벤트가 중복으로 붙지 않도록 처리했다.
동작 원리
스크립트 내부에서는 두벌식 한글 자모를 QWERTY 키 입력으로 되돌리는 매핑 테이블을 사용한다.
예를 들어 한글 상태에서 영문 키를 누르면 다음처럼 입력될 수 있다.
a → ㅁ
c → ㅊ
e → ㄷ
그래서 ㅁㅊㄷ이 들어오면 다시 ace로 되돌리고, 최종적으로 ACE로 대문자 변환한다.
완성형 한글이 들어온 경우도 고려했다.
완성형 한글은 초성, 중성, 종성으로 분해한 뒤 각각을 QWERTY 키 입력으로 변환한다.
또한 단순히 CSS로 대문자로 보이게 만드는 방식은 사용하지 않았다.
text-transform: uppercase;
이 방식은 화면에는 대문자로 보이지만, 실제 입력값은 소문자로 남을 수 있다.
S/N은 복사해서 다른 곳에 붙여넣거나 서버로 전송하는 값이 중요하기 때문에, 실제 input.value 자체를 대문자로 정리하도록 했다.
신경 쓴 부분
이 스크립트는 페이지 전체 키 입력을 건드리지 않는다.
S/N 입력창으로 지정한 input 안에서만 동작한다.
그래야 다른 검색창, 메모 입력창, 일반 텍스트 입력에 영향을 주지 않는다.
그리고 입력 방식도 하나만 가정하지 않았다.
- 직접 키보드 입력
- 바코드 리더기 스캔
- 복사/붙여넣기
이 세 가지 입력을 모두 같은 정규화 로직으로 처리하도록 했다.
업무용 전산에서는 사용자가 항상 같은 방식으로 입력한다고 가정하면 문제가 생기기 쉽다.
그래서 입력 경로가 달라도 최종 결과는 동일하게 맞추는 방향으로 구현했다.
적용 전후
적용 전에는 한글 입력 상태에서 S/N을 스캔하면 값이 깨질 수 있었다.
ACE123 → ㅁㅊㄷ123
적용 후에는 한글 입력 상태여도 최종 값이 영문 대문자로 정리된다.
ㅁㅊㄷ123 → ACE123
작은 차이지만, 반복 업무에서는 체감이 크다.
잘못 입력된 값을 지우고, 한/영 키를 누르고, 다시 스캔하는 과정이 사라진다.
특히 여러 제품의 S/N을 연속으로 입력해야 하는 상황에서는 실수와 재작업을 줄일 수 있다.
한계
이 스크립트는 S/N처럼 영문과 숫자 중심의 값을 입력하는 경우에 맞춰 만들었다.
기본 설정에서는 영문과 숫자만 남기고 나머지 문자는 제거한다.
따라서 하이픈, 언더스코어, 공백 같은 문자가 필요한 S/N 체계라면 허용 문자 규칙을 조정해야 한다.
또한 모든 업무 시스템에 그대로 붙일 수 있는 범용 솔루션이라기보다는, 특정 입력창에 가볍게 적용하는 보정 스크립트에 가깝다.
마무리
이번 작업은 큰 기능을 만든 것은 아니다.
하지만 실제 업무에서는 이런 작은 불편이 반복적으로 시간을 잡아먹는다.
입력 전에 한/영 상태를 확인하세요.
이렇게 사용자에게 맡기는 대신, 입력창이 알아서 보정하도록 만들면 실수 가능성을 줄일 수 있다.
개인적으로는 이런 도구가 업무 자동화의 시작이라고 생각한다.
거창한 시스템을 새로 만드는 것도 좋지만,
현장에서 매일 반복되는 작은 불편을 하나씩 없애는 것만으로도 충분히 의미 있는 개선이 된다.
작성자: